先贴上目前(2018.12)消费级(游戏级)显卡最新的产品RTX 2080ti作为基准线。
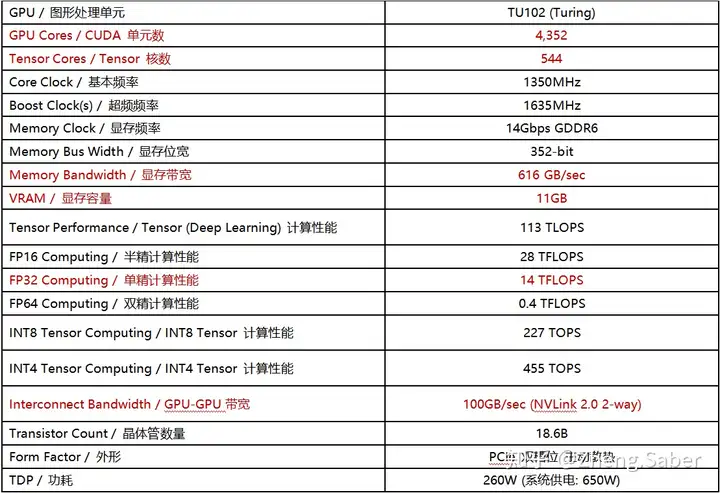
(知乎不能编写表格吗?是我不会还是本来就不支持,求大佬们教育)
重点需要关注的参数我已经标红啦,主要讲一下这些参数在深度学习中的意义,方便以后对比自己的项目需求来做增删。
GPU架构:GPU架构指的是硬件的设计方式,例如流处理器簇中有多少个core、是否有L1 or L2缓存、是否有双精度计算单元等等。每一代的架构是一种思想,如何去更好完成并行的思想,而芯片就是对上述思想的实现。目前N家主流架构有图灵(Turing)、帕斯卡(Pascal)、开普勒(Kepler)、Volta等。一般GPU加速卡以GPU架构命名其型号的首字母,如:P100为帕斯卡(Pascal)架构。当然也有类似2080ti这种命名方式,其为图灵(Turing)架构(我觉得目的是区分Tesla,不知道对不对)。
CUDA单元数:CUDA(Compute Unified Device Architecture)是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 基本上目前做深度学习的话没有人不知道CUDA的大名吧,这个单元数直接影响GPU的计算性能。
Tensor核心数:我们知道在深度学习中大量的运算都是在高维矩阵(张量 Tensor)间进行的,Tensor Core可以让tensor的计算速度急速上升。Tensor Core专业执行矩阵数学运算,适用于深度学习和某些类型的HPC。Tensor Core执行融合乘法加法,其中两个4*4 FP16矩阵相乘,然后将结果添加到4*4 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。NVIDIA将Tensor Core进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。碰巧的是,Tensor Core所做的这种运算在深度学习训练和推理中很常见。Tensor Core在GPU里处理的是大型矩阵运算,而不是简单地单指令流多数据流标量运算。虽然它在执行标量运算时的表现很糟糕,但它可以将更多的操作打包到同一个芯片区域。
显存带宽:显存带宽是指显示芯片与显存之间的数据传输速率。据我的观察,如果我们在做图像方面的深度学习研究的话,一个具有较大显存带宽的GPU允许你在设置较大的batch_size,也就是你可以同时拿出来较多的数据来一起训练。
显存容量:显存容量是显卡上显存的容量数,显存容量决定着显存临时存储数据的多少。还是举做图像方面的研究的例子,一个较大的显存容量能让你一次性把更多的训练图片读入内存中,甚至可以将整个数据集直接存入一个变量里面,感觉比写个像tfrecord这种队列或者堆栈去慢慢读数据要爽的多,至少可以解决shuffle不充分的问题嘛~
双/单/半精度计算性能:这个当然是最重要的,这个指标就是GPU在处理FP64/FP32/FP16不同精度的浮点数时的浮点计算能力。对于浮点计算来说,CPU可以同时支持不同精度的浮点运算,但在GPU里针对单精度和双精度就需要各自独立的计算单元。所以这里就要看所做项目是否有必要到双精度计算的级别,一般来说深度学习计算中精度要求都很低,没有哪个权值矩阵小数点后十几位的变化对最终结果有较大影响的,不然就要考虑是不是病态了。
差不多就这些吧,以后测试的时候想起来再补充~
搞清楚这些参数我们再来看看V100/P100/P40的对比图:
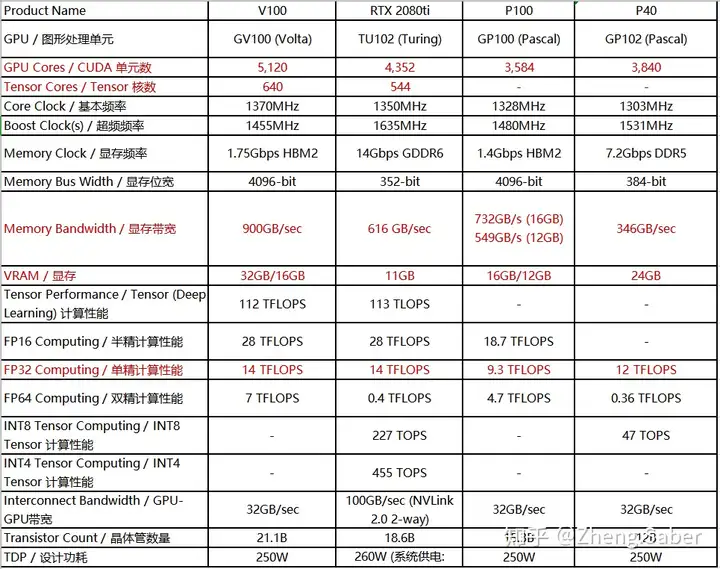
是不是就一目了然了,最后再简单总结一下:
在训练时间短,需要快速完成训练的项目来说,即大程度考虑GPU低精度计算速度的情况下:
V100>2080ti>P100>=P40 (P40不支持半精度计算但单精度优于P100,P40带宽低但显存高)
2. 不急着训练出结果,但数据集特别大,比如图像、视频流的处理项目:
V100>P40>P100>2080ti(要求显存和带宽高)
3. 在数据集为NLP方面或时序数据且预算不太充足,即数据量不大的情况下:
2080ti>P40>P100>V100(V100实在有点贵)
4. 我不光想用它做深度学习,还想用来当个数据中心:
V100(同时运行GPU与CPU服务器的数据中心&深度学习大模型算例的并行计算)
P100(同时运行GPU与CPU服务器的数据中心&一般规模的深度学习)
P40(简化数据中心级的模型训练的推理&超大规模科学计算)
2080ti(大规模深度学习计算&大型游戏?)
写在最后
本人也是硬件小白,最近恶补了一波之后记录于此,也方便大家交流,有什么写错或者词不达意的地方请大家指正,谢谢~